篇首语:本文由编程笔记#小编为大家整理,主要介绍了推理加速GPT-3超越英伟达方案50%,开源方案打通大模型落地关键路径相关的知识,希望对你有一定的参考价值。
篇首语:本文由编程笔记#小编为大家整理,主要介绍了推理加速 GPT-3 超越英伟达方案50%,开源方案打通大模型落地关键路径相关的知识,希望对你有一定的参考价值。
伴随着深度学习模型规模的指数型增长,常见的单卡推理解决方案已然无法满足前沿AI大模型的推理需求。例如1750亿参数的GPT-3模型,仅仅是加载模型参数就需要数百GB的存储空间,远超单个GPU的容纳能力。因此,对于AI大模型使用多卡并行的方式进行推理已成为必然选择。
针对现有推理系统的这一痛点,Colossal-AI团队以“高性能、高可用、可伸缩”的理念,深入单实例多设备推理场景,开发了大模型推理系统Energon-AI,在性能和易用性上兼具优势:
仅需对现有项目进行极少量修改,用户便可完成自定义大模型的推理部署,获得并行扩展的超线性加速,对于AI大模型分布式推理加速,相比英伟达FasterTransformer可提升50%以上。
相比现有推理方案,Energon-AI不再需要用户对通信、内存等各部分协作进行手动管理,也无需额外编译,大幅降低了用户的使用门槛。
开源地址:https://github.com/hpcaitech/ColossalAI
AI大模型推理部署的困难
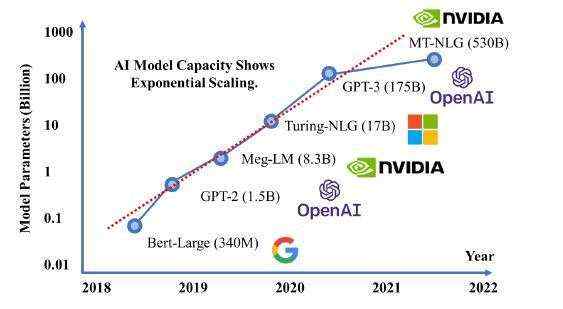
模型参数的迅速增长[https://arxiv.org/abs/2111.14247]
近年来,计算设备(如GPU)的并行计算能力、内存容量,内存速度等都得到了极大的增强,然而,单设备纵向扩展(scale up)的性能增益在面对指数型增长的模型规模时,仍难以满足大模型的内存与性能需求。而当前的深度学习推理系统,主要面向多实例单设备以及单实例单设备的简单推理场景,忽视了AI大模型推理所需要的单实例多设备的挑战与机遇,Energon-AI系统正是为了解决这一痛点而生。
Energon-AI系统设计
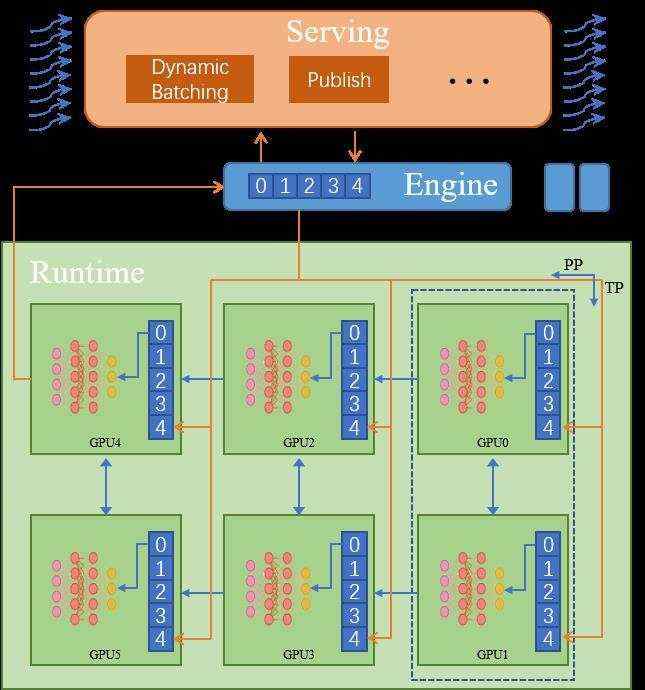
Energon-AI超大模型推理系统示意图
面向AI大模型部署,我们设计了单实例多设备推理系统Energon-AI。Energon-AI系统设计分为三个层次,即运行时系统(Runtime)、分布式推理实例(Engine)以及前端服务系统(Serving):
• Runtime:在运行时系统设计过程中我们发现,当模型规模不断增大,通用矩阵乘的时间占比逐渐增大,而访存密集型算子与Kernel Launch的时间占比则逐渐降低,推理过程进一步从访存密集型向计算密集型方向迁移,TensorRT以及专用推理系统对访存密集型操作的优化效果被极大削减。Energon-AI Runtime依赖于Colossal-AI实现张量并行,同时设计了流水线并行包装方法用于显存不足的情况。此外,我们引入了大量推理专用算子及方法。如,面对NLP中输入变长的特点,我们引入了transpose_padding_rebulid与transpose_padding_remove等算子用以高效支持Encoder和Decoder模型中MLP层的冗余计算消除方法。
• Engine:单设备推理中程序有相同的数据入口与出口,分布式训练的主要目标是模型参数,因此无须对多个进程的输入输出进行管理,而多设备推理则不同。我们希望通过良好的封装使得Engine具有与单设备推理完全相同的行为。我们采用了半中心化方法,主进程中使用RPC在每个设备调用初始化或推理方法,使得分布式推理可以得到中心化的控制,同时每个设备则保有自己的Tensor Parallel与Pipeline Parallel通信逻辑。我们在每个进程中设计并维护了分布式消息队列,用以保证多个进程中多线程调用执行的一致性。
• Serving:针对用户请求分散和变长的特点及大模型推理对GPU并行运算的依赖之间的矛盾,Energon-AI引入了动态Batching机制,将请求队列中的请求按照机器性能进行最优打包后,根据等候时间、batch大小、batch的扩展可能性(根据padding后的句子长度)等挑选优先级最高的batch处理,最大化GPU使用率的同时规避饥饿问题,减小平均请求时延。
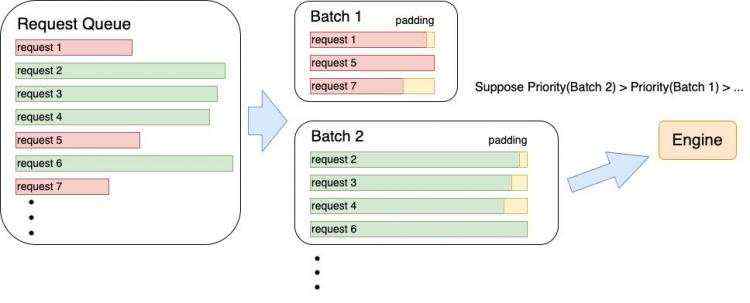 Batch管理流程示意图
Batch管理流程示意图
性能测试
并行推理超线性扩展
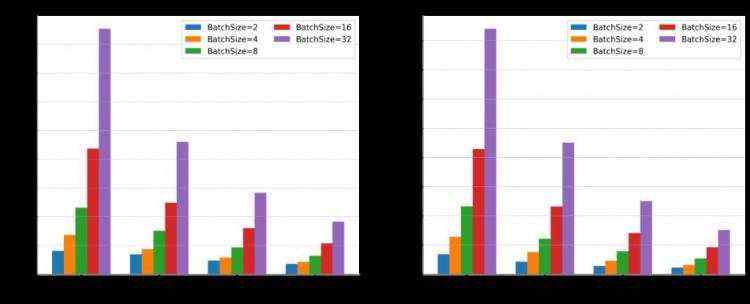
张量并行可扩展性测试结果展示。硬件环境:8 * A100 GPU 80GB。由于单设备显存无法满足GPT-3推理需求,此处为GPT-3 12层的测试结果,设置句长为Padding的1/2。
Energon-AI八卡并行推理在Batch Size为32时,相比于单卡Pytorch直接推理,可获得8.5倍的超线性加速。
运行时推理性能提升50%
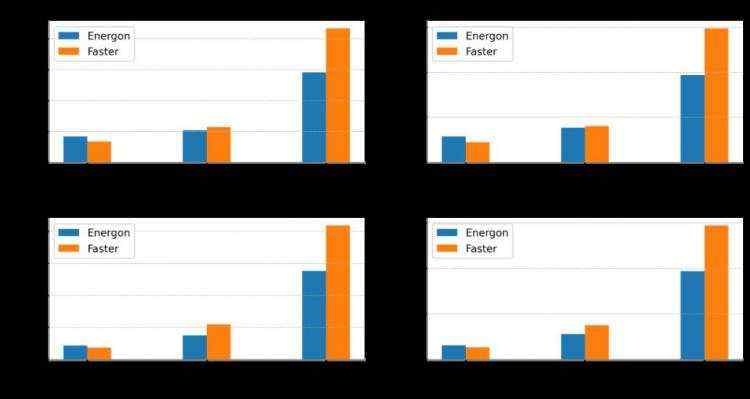
张量并行运行时系统推理时延对比。硬件环境:8 * A100 GPU 80GB。
设置句长为Padding的1/2。GPT-3-24-Layers for TP=2, GPT-3-48-Layers for TP=4。
我们选择高度优化的英伟达FasterTransformer GPT-3作为对比方案。FasterTransformer在其4.0版本中推出了分布式推理特性,目前支持GPT-3模型的分布式推理,但由于其纯C++代码高度耦合的特点,灵活度与易用性相对较低。此外,对于NLP推理输入句长不同的特点,其分布式推理无冗余计算消除功能。
对于GPT-3模型,Energon-AI的运行时系统在Batch Size为1时性能略低于FasterTransformer,而在Batch Size较大时能够实现超过50%的性能提升。
Dynamic Batching 吞吐量增加30%

Dynamic batching与直接打包batch吞吐量对比。硬件环境:8 * A100 GPU 80GB。测试使用的模型为GPT-3, 测试句长为256以内随机生成,padding策略为batch内最长padding。
我们模拟真实场景下多用户同时发送大量变长推理请求的情况,将我们的动态batch规划方法与传统的FIFO(先入先出)队列打包方法进行了吞吐量对比。由于dynamic batching的算法缓解了直接padding造成的大量冗余计算问题,在该策略下dynamic batching的吞吐量实现了34.7%的提升。
易用性
Python
from gpt import gpt3
from gpt_server import launch_engine
# for engine
model_class = gpt3
model_type = "gpt"
host = "127.0.0.1"
port = 29400
half = True
backend = "nccl"
# for parallel
tp_init_size = 4
pp_init_size = 2
# for server
engine_server = launch_engine
server_host = "127.0.0.1"
server_port = 8020
rm_padding = True
Python
energonai service init --config_file=gpt_config.py
在追求性能的同时,Energon-AI希望保持系统使用的灵活度与易用性,用户仅需自定义【并行模型】、【并行参数】以及【服务请求逻辑】加入到配置文件中,即可启动推理服务。目前,我们提供了最常见的GPT、BERT和ViT模型作为示例,更详尽的教程将会在近期完善。
在构建新的并行模型时,Energon-AI使用Python,且使用方式与Pytorch相似,有层的概念且初始化与执行逻辑清晰,用户无需考虑内存管理,并行通信等行为。如下代码展示了两层Linear层组成的模型并行运行的完整代码。
Python
class MLP(nn.Module):
def __init__(self, dim, dtype, bias):
super().__init__()
self.dense_0 = Linear1D_Col(dim, dim, dtype=dtype, bias=bias, gather_output=False)
self.dense_1 = Linear1D_Row(dim, dim, dtype=dtype, bias=bias, parallel_input=True)
def forward(self, x):
x = self.dense_0(x)
x = self.dense_1(x)
return x
与之相对,在构建新的并行模型时,FasterTransformer需要使用C++代码并且需要用户自行进行内存管理,定义通信等底层行为组织。受篇幅限制,如下代码展示两层Linear层模型并行运行的内存管理,具体执行,通信的部分代码。除此之外,用户想要代码正确执行,还需要花费大量时间精力对内存管理、执行逻辑、通信行为之间的配合进行调试,C++代码还需要额外编译工作。这些都对用户的并行知识与编程能力提出了严峻挑战。
C++
// Memory Allocation (only for a single paramerter).
T *d_inter_kernel = NULL
param_.ffn.intermediate_weight.kernel = d_inter_kernel;
device_malloc(&d_inter_kernel, dim * dim);
// Two MLP Layers
cublasMM_cublasLtMM_wrapper(param_.cublaslt_handle, param_.cublas_handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, &alpha, param_.ffn.intermediate_weight.kernel, AType_, n, attr_matmul_buf_, BType_, k, &beta, (DataType_ *)inter_matmul_buf_, CType_, n, param_.stream, cublasAlgoMap_, sm_, cublas_workspace_);
add_bias_act_kernelLauncher(inter_matmul_buf_, param_.ffn.intermediate_weight.bias, m, n, ActivationType::GELU, param_.stream);
n = k;
cublasMM_cublasLtMM_wrapper(param_.cublaslt_handle, param_.cublas_handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, &alpha, param_.ffn.output_weight.kernel, AType_, n, inter_matmul_buf_, BType_, k, &beta, (DataType_ *)(param_.transformer_out), CType_, n, param_.stream, cublasAlgoMap_, sm_, cublas_workspace_);
add_bias_input_layernorm_kernelLauncher(param_.transformer_out, attr_matmul_buf_, param_.ffn.output_weight.bias, param_.ffn_layernorm.gamma, param_.ffn_layernorm.beta, m, n, param_.stream);
// Communication
if(t_parallel_param_.world_size > 1)
all2all_gather(nccl_logits_buf_, nccl_logits_buf_, local_batch * n, t_parallel_param_, decoding_params.stream);
更多特性
本次发布的Energon-AI子系统为beta版,近期会根据用户反馈与既定计划,进行密集的迭代更新,尽早为用户提供正式版,充分满足用户的不同推理部署需求,欢迎向Energon-AI提出您的需求与建议。
构建AI大模型生态系统
面对AI大模型的时代浪潮,除了本次新增的推理部署特性,针对现有大模型训练方案并行维度有限、效率不高、通用性差、部署困难、缺乏维护等痛点,Colossal-AI通过高效多维并行和异构并行等技术,让用户仅需极少量修改,即可高效快速部署AI大模型训练。
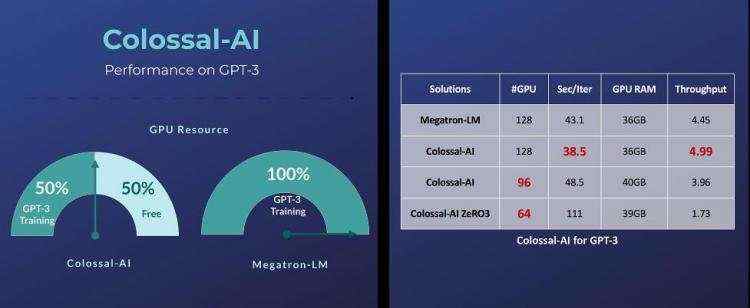
例如对于GPT-3这样的超大AI模型,相比英伟达方案,Colossal-AI仅需一半的计算资源,即可启动训练;若使用相同计算资源,则能提速11%,可降低GPT-3训练成本超百万美元。
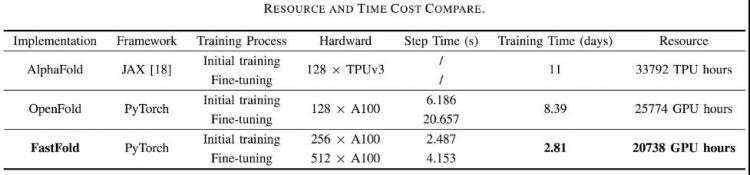
对于蛋白质结构预测应用AlphaFold,基于Colossal-AI的加速方案的FastFold,成功超越谷歌和哥伦比亚大学的方案,将AlphaFold训练时间从11天减少到67小时,且总成本更低,在长序列推理中也实现9.3~11.6倍的速度提升。
Colossal-AI兼容低端设备,在仅有一块GPU的个人PC上便能训练高达180亿参数GPT;普通的笔记本电脑,也能训练十几亿参数的模型,相比现有主流方案,可提升参数容量十余倍,大幅度降低了AI大模型微调和推理等下游任务和应用部署的门槛。

Colossal-AI注重开源社区建设,提供中文教程,开放用户社群及论坛,对于用户反馈进行高效交流与迭代更新,不断添加等前沿特性。
自然开源以来,Colossal-AI已经多次登上GitHub热榜Python方向世界第一,与众多已有数万star的明星开源项目一起受到海内外关注!
在反映机器学习领域热点的Papers With Code网站上,Colossal-AI也广受关注,荣登热榜第一。
传送门
项目地址:https://github.com/hpcaitech/ColossalAI
参考链接:https://medium.com/@hpcaitech/6139c5bc7790










 京公网安备 11010802041100号
京公网安备 11010802041100号